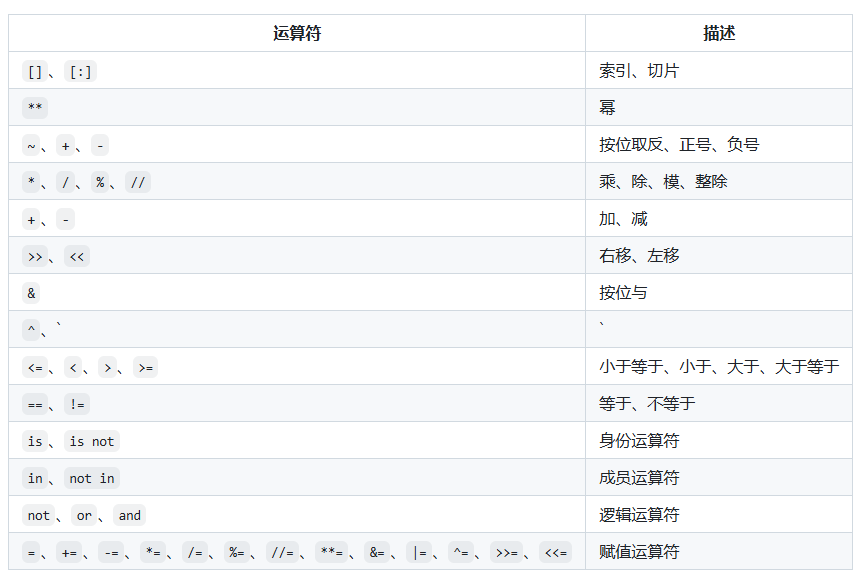
import random
f1 = 0
f2 = 0
f3 = 0
f4 = 0
f5 = 0
f6 = 0
for _ in range(6000):
face = random.randrange(1, 7)
if face == 1:
f1 += 1
elif face == 2:
f2 += 1
elif face == 3:
f3 += 1
elif face == 4:
f4 += 1
elif face == 5:
f5 += 1
else:
f6 += 1
print(f'1点出现了{f1}次')
print(f'2点出现了{f2}次')
print(f'3点出现了{f3}次')
print(f'4点出现了{f4}次')
print(f'5点出现了{f5}次')
print(f'6点出现了{f6}次')上面的代码模拟了骰子数字的出现,如果我们要掷两颗或者掷更多的色子,然后统计每种点数出现的次数,那就需要定义更多的变量,写更多的分支结构,非常麻烦。在 Python 语言中我们可以通过容器型变量来保存和操作多个数据,所以有列表(list)这种新的数据类型。
创建列表
在 Python 中,列表是由一系元素按特定顺序构成的数据序列,这就意味着如果我们定义一个列表类型的变量,可以用它来保存多个数据。在 Python 中,可以使用[]字面量语法来定义列表,列表中的多个元素用逗号进行分隔,代码如下所示。
items1 = [35, 12, 99, 68, 55, 35, 87]
items2 = ['Python', 'Java', 'Go', 'Kotlin']
items3 = [100, 12.3, 'Python', True]
print(items1) # [35, 12, 99, 68, 55, 35, 87]
print(items2) # ['Python', 'Java', 'Go', 'Kotlin']
print(items3) # [100, 12.3, 'Python', True]列表中可以有重复元素,例如items1中的35;列表中可以有不同类型的元素,例如items3中有int类型、float类型、str类型和bool类型的元素,但是我们通常并不建议将不同类型的元素放在同一个列表中,主要是操作起来极为不便。
我们可以使用type函数来查看变量的类型。因为列表可以保存多个元素,它是一种容器型的数据类型,所以我们在给列表类型的变量起名字时,变量名通常用复数形式的单词。
除此以外,还可以通过 Python 内置的list函数将其他序列变成列表。准确的说,list并不是一个普通的函数,它是创建列表对象的构造器。
items4 = list(range(1, 10))
items5 = list('hello')
print(items4) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(items5) # ['h', 'e', 'l', 'l', 'o']range(1, 10)会产生1到9的整数序列,给到list构造器中,会创建出由1到9的整数构成的列表。字符串是字符构成的序列,上面的list('hello')用字符串hello的字符作为列表元素,创建了列表对象。
列表的运算
我们可以使用+运算符实现两个列表的拼接,拼接运算会将两个列表中的元素连接起来放到一个列表中,代码如下所示。
items5 = [35, 12, 99, 45, 66]
items6 = [45, 58, 29]
items7 = ['Python', 'Java', 'JavaScript']
print(items5 + items6) # [35, 12, 99, 45, 66, 45, 58, 29]
print(items6 + items7) # [45, 58, 29, 'Python', 'Java', 'JavaScript']
items5 += items6
print(items5) # [35, 12, 99, 45, 66, 45, 58, 29]我们可以使用*运算符实现列表的重复运算,*运算符会将列表元素重复指定的次数,我们在上面的代码中增加两行,如下所示。
print(items6 * 3) # [45, 58, 29, 45, 58, 29, 45, 58, 29]
print(items7 * 2) # ['Python', 'Java', 'JavaScript', 'Python', 'Java', 'JavaScript']我们可以使用in或not in运算符判断一个元素在不在列表中,我们在上面的代码代码中再增加两行,如下所示。
print(29 in items6) # True
print(99 in items6) # False
print('C++' not in items7) # True
print('Python' not in items7) # False由于列表中有多个元素,而且元素是按照特定顺序放在列表中的,所以当我们想操作列表中的某个元素时,可以使用[]运算符,通过在[]中指定元素的位置来访问该元素,这种运算称为索引运算。需要说明的是,[]的元素位置可以是0到N - 1的整数,也可以是-1到-N的整数,分别称为正向索引和反向索引,其中N代表列表元素的个数。对于正向索引,[0]可以访问列表中的第一个元素,[N - 1]可以访问最后一个元素;对于反向索引,[-1]可以访问列表中的最后一个元素,[-N]可以访问第一个元素,代码如下所示。
items8 = ['apple', 'waxberry', 'pitaya', 'peach', 'watermelon']
print(items8[0]) # apple
print(items8[2]) # pitaya
print(items8[4]) # watermelon
items8[2] = 'durian'
print(items8) # ['apple', 'waxberry', 'durian', 'peach', 'watermelon']
print(items8[-5]) # 'apple'
print(items8[-4]) # 'waxberry'
print(items8[-1]) # watermelon
items8[-4] = 'strawberry'
print(items8) # ['apple', 'strawberry', 'durian', 'peach', 'watermelon']在使用索引运算的时候要避免出现索引越界的情况,对于上面的items8,如果我们访问items8[5]或items8[-6],就会引发IndexError错误,导致程序崩溃,对应的错误信息是:list index out of range,翻译成中文就是“数组索引超出范围”。因为对于只有五个元素的列表items8,有效的正向索引是0到4,有效的反向索引是-1到-5。
如果希望一次性访问列表中的多个元素,我们可以使用切片运算。切片运算是形如[start:end:stride]的运算符,其中start代表访问列表元素的起始位置,end代表访问列表元素的终止位置(终止位置的元素无法访问),而stride则代表了跨度,简单的说就是位置的增量,比如我们访问的第一个元素在start位置,那么第二个元素就在start + stride位置,当然start + stride要小于end。我们给上面的代码增加下面的语句,来使用切片运算符访问列表元素。
print(items8[1:3:1]) # ['strawberry', 'durian']
print(items8[0:3:1]) # ['apple', 'strawberry', 'durian']
print(items8[0:5:2]) # ['apple', 'durian', 'watermelon']
print(items8[-4:-2:1]) # ['strawberry', 'durian']
print(items8[-2:-6:-1]) # ['peach', 'durian', 'strawberry', 'apple']如果start值等于0,那么在使用切片运算符时可以将其省略;如果end值等于N,N代表列表元素的个数,那么在使用切片运算符时可以将其省略;如果stride值等于1,那么在使用切片运算符时也可以将其省略。所以,下面的代码跟上面的代码作用完全相同。
print(items8[1:3]) # ['strawberry', 'durian']
print(items8[:3:1]) # ['apple', 'strawberry', 'durian']
print(items8[::2]) # ['apple', 'durian', 'watermelon']
print(items8[-4:-2]) # ['strawberry', 'durian']
print(items8[-2::-1]) # ['peach', 'durian', 'strawberry', 'apple']事实上,我们还可以通过切片操作修改列表中的元素,例如我们给上面的代码再加上一行,大家可以看看这里的输出。
items8[1:3] = ['x', 'o']
print(items8) # ['apple', 'x', 'o', 'peach', 'watermelon']两个列表还可以做关系运算,我们可以比较两个列表是否相等,也可以给两个列表比大小,代码如下所示。
nums1 = [1, 2, 3, 4]
nums2 = list(range(1, 5))
nums3 = [3, 2, 1]
print(nums1 == nums2) # True
print(nums1 != nums2) # False
print(nums1 <= nums3) # True
print(nums2 >= nums3) # False上面的nums1和nums2对应元素完全相同,所以==运算的结果是True。nums2和nums3的比较,由于nums2的第一个元素1小于nums3的第一个元素3,所以nums2 >= nums3比较的结果是False。两个列表的关系运算在实际工作并不那么常用,如果实在不理解就跳过吧,不用纠结。
元素的遍历
如果想逐个取出列表中的元素,可以使用for-in循环的,有以下两种做法。
方法一:在循环结构中通过索引运算,遍历列表元素。
languages = ['Python', 'Java', 'C++', 'Kotlin']
for index in range(len(languages)):
print(languages[index])说明:上面的
len函数可以获取列表元素的个数N,而range(N)则构成了从0到N-1的范围,刚好可以作为列表元素的索引。
方法二:直接对列表做循环,循环变量就是列表元素的代表。
languages = ['Python', 'Java', 'C++', 'Kotlin']
for language in languages:
print(language)输出:
Python
Java
C++
Kotlin我们可以用列表的知识来重构上面“掷色子统计每种点数出现次数”的代码。
import random
counters = [0] * 6
# 模拟掷色子记录每种点数出现的次数
for _ in range(6000):
face = random.randrange(1, 7)
counters[face - 1] += 1
# 输出每种点数出现的次数
for face in range(1, 7):
print(f'{face}点出现了{counters[face - 1]}次')上面的代码中,我们用counters列表中的六个元素分别表示 1 到 6 点出现的次数,最开始的时候六个元素的值都是 0。接下来,我们用 1 到 6 均匀分布的随机数模拟掷色子,如果摇出 1 点,counters[0]的值加 1,如果摇出 2 点,counters[1]的值加 1,以此类推。大家感受一下,由于使用了列表类型加上循环结构,我们对数据的处理是批量性的,这就使得修改后的代码比之前的代码要简单优雅得多。
列表的方法
列表类型的变量拥有很多方法可以帮助我们操作一个列表,假设我们有名为foos的列表,列表有名为bar的方法,那么使用列表方法的语法是:foos.bar(),这是一种通过对象引用调用对象方法的语法。后面我们讲面向对象编程的时候,还会对这种语法进行详细的讲解,这种语法也称为给对象发消息。
添加和删除元素
列表是一种可变容器,可变容器指的是我们可以向容器中添加元素、可以从容器移除元素,也可以修改现有容器中的元素。我们可以使用列表的append方法向列表中追加元素,使用insert方法向列表中插入元素。追加指的是将元素添加到列表的末尾,而插入则是在指定的位置添加新元素,大家可以看看下面的代码。
languages = ['Python', 'Java', 'C++']
languages.append('JavaScript')
print(languages) # ['Python', 'Java', 'C++', 'JavaScript']
languages.insert(1, 'SQL')
print(languages) # ['Python', 'SQL', 'Java', 'C++', 'JavaScript']我们可以用列表的remove方法从列表中删除指定元素,需要注意的是,如果要删除的元素并不在列表中,会引发ValueError错误导致程序崩溃,所以建议大家在删除元素时,先用之前讲过的成员运算做一个判断。我们还可以使用pop方法从列表中删除元素,pop方法默认删除列表中的最后一个元素,当然也可以给一个位置,删除指定位置的元素。在使用pop方法删除元素时,如果索引的值超出了范围,会引发IndexError异常,导致程序崩溃。除此之外,列表还有一个clear方法,可以清空列表中的元素,代码如下所示。
languages = ['Python', 'SQL', 'Java', 'C++', 'JavaScript']
if 'Java' in languages:
languages.remove('Java')
if 'Swift' in languages:
languages.remove('Swift')
print(languages) # ['Python', 'SQL', C++', 'JavaScript']
languages.pop()
temp = languages.pop(1)
print(temp) # SQL
languages.append(temp)
print(languages) # ['Python', C++', 'SQL']
languages.clear()
print(languages) # []pop方法删除元素时会得到被删除的元素,上面的代码中,我们将pop方法删除的元素赋值给了名为temp的变量。当然如果你愿意,还可以把这个元素再次加入到列表中,正如上面的代码languages.append(temp)所做的那样。
这里还有一个小问题,例如languages列表中有多个'Python',那么我们用languages.remove('Python')是删除所有的'Python',还是删除第一个'Python',大家可以先猜一猜,然后再自己动手尝试一下。
从列表中删除元素其实还有一种方式,就是使用 Python 中的del关键字后面跟要删除的元素,这种做法跟使用pop方法指定索引删除元素没有实质性的区别,但后者会返回删除的元素,前者在性能上略优,因为del对应的底层字节码指令是DELETE_SUBSCR,而pop对应的底层字节码指令是CALL_METHOD和POP_TOP,如果不理解就不用管它了。
items = ['Python', 'Java', 'C++']
del items[1]
print(items) # ['Python', 'C++']元素位置和频次
列表的index方法可以查找某个元素在列表中的索引位置,如果找不到指定的元素,index方法会引发ValueError错误;列表的count方法可以统计一个元素在列表中出现的次数,代码如下所示。
items = ['Python', 'Java', 'Java', 'C++', 'Kotlin', 'Python']
print(items.index('Python')) # 0
# 从索引位置1开始查找'Python'
print(items.index('Python', 1)) # 5
print(items.count('Python')) # 2
print(items.count('Kotlin')) # 1
print(items.count('Swfit')) # 0
# 从索引位置3开始查找'Java'
print(items.index('Java', 3)) # ValueError: 'Java' is not in list元素排序和反转
列表的sort操作可以实现列表元素的排序,而reverse操作可以实现元素的反转,代码如下所示。
items = ['Python', 'Java', 'C++', 'Kotlin', 'Swift']
items.sort()
print(items) # ['C++', 'Java', 'Kotlin', 'Python', 'Swift']
items.reverse()
print(items) # ['Swift', 'Python', 'Kotlin', 'Java', 'C++']列表生成式
在 Python 中,列表还可以通过一种特殊的字面量语法来创建,这种语法叫做生成式。下面,我们通过例子来说明使用列表生成式创建列表到底有什么好处。
场景一:创建一个取值范围在1到99且能被3或者5整除的数字构成的列表。
items = []
for i in range(1, 100):
if i % 3 == 0 or i % 5 == 0:
items.append(i)
print(items)使用列表生成式做同样的事情,代码如下所示。
items = [i for i in range(1, 100) if i % 3 == 0 or i % 5 == 0]
print(items)场景二:有一个整数列表nums1,创建一个新的列表nums2,nums2中的元素是nums1中对应元素的平方。
nums1 = [35, 12, 97, 64, 55]
nums2 = []
for num in nums1:
nums2.append(num ** 2)
print(nums2)使用列表生成式做同样的事情,代码如下所示。
nums1 = [35, 12, 97, 64, 55]
nums2 = [num ** 2 for num in nums1]
print(nums2)场景三: 有一个整数列表nums1,创建一个新的列表nums2,将nums1中大于50的元素放到nums2中。
nums1 = [35, 12, 97, 64, 55]
nums2 = []
for num in nums1:
if num > 50:
nums2.append(num)
print(nums2)使用列表生成式做同样的事情,代码如下所示。
nums1 = [35, 12, 97, 64, 55]
nums2 = [num for num in nums1 if num > 50]
print(nums2)使用列表生成式创建列表不仅代码简单优雅,而且性能上也优于使用for-in循环和append方法向空列表中追加元素的方式。为什么说生成式有更好的性能呢,那是因为 Python 解释器的字节码指令中有专门针对生成式的指令(LIST_APPEND指令);而for循环是通过方法调用(LOAD_METHOD和CALL_METHOD指令)的方式为列表添加元素,方法调用本身就是一个相对比较耗时的操作。对这一点不理解也没有关系,记住“强烈建议用生成式语法来创建列表”这个结论就可以了。
嵌套列表
Python 语言没有限定列表中的元素必须是相同的数据类型,也就是说一个列表中的元素可以任意的数据类型,当然也包括列表本身。如果列表中的元素也是列表,那么我们可以称之为嵌套的列表。嵌套的列表可以用来表示表格或数学上的矩阵,例如:我们想保存5个学生3门课程的成绩,可以用如下所示的列表。
scores = [[95, 83, 92], [80, 75, 82], [92, 97, 90], [80, 78, 69], [65, 66, 89]]
print(scores[0])
print(scores[0][1])对于上面的嵌套列表,每个元素相当于就是一个学生3门课程的成绩,例如[95, 83, 92],而这个列表中的83代表了这个学生某一门课的成绩,如果想访问这个值,可以使用两次索引运算scores[0][1],其中scores[0]可以得到[95, 83, 92]这个列表,再次使用索引运算[1]就可以获得该列表中的第二个元素。
如果想通过键盘输入的方式来录入5个学生3门课程的成绩并保存在列表中,可以使用如下所示的代码。
scores = []
for _ in range(5):
temp = []
for _ in range(3):
score = int(input('请输入: '))
temp.append(score)
scores.append(temp)
print(scores)如果想通过产生随机数的方式来生成5个学生3门课程的成绩并保存在列表中,我们可以使用列表生成式,代码如下所示。
import random
scores = [[random.randrange(60, 101) for _ in range(3)] for _ in range(5)]
print(scores)上面的代码[random.randrange(60, 101) for _ in range(3)] 可以产生由3个随机整数构成的列表,我们把这段代码又放在了另一个列表生成式中作为列表的元素,这样的元素一共生成5个,最终得到了一个嵌套列表。
列表的应用
下面我们通过一个双色球随机选号的例子为大家讲解列表的应用。双色球是由中国福利彩票发行管理中心发售的乐透型彩票,每注投注号码由6个红色球和1个蓝色球组成。红色球号码从1到33中选择,蓝色球号码从1到16中选择。每注需要选择6个红色球号码和1个蓝色球号码,如下所示。
import random
red_balls = list(range(1, 34))
selected_balls = []
# 添加6个红色球到选中列表
for _ in range(6):
# 生成随机整数代表选中的红色球的索引位置
index = random.randrange(len(red_balls))
# 将选中的球从红色球列表中移除并添加到选中列表
selected_balls.append(red_balls.pop(index))
# 对选中的红色球排序
selected_balls.sort()
# 输出选中的红色球
for ball in selected_balls:
print(f'\033[031m{ball:0>2d}\033[0m', end=' ')
# 随机选择1个蓝色球
blue_ball = random.randrange(1, 17)
# 输出选中的蓝色球
print(f'\033[034m{blue_ball:0>2d}\033[0m')上面代码中print(f'\033[0m...\033[0m')是为了控制输出内容的颜色,红色球输出成红色,蓝色球输出成蓝色。其中省略号代表我们要输出的内容,\033[0m是一个控制码,表示关闭所有属性,也就是说之前的控制码将会失效,你也可以将其简单的理解为一个定界符,m前面的0表示控制台的显示方式为默认值,0可以省略,1表示高亮,5表示闪烁,7表示反显等。在0和m的中间,我们可以写上代表颜色的数字,比如30代表黑色,31代表红色,32代表绿色,33代表黄色,34代表蓝色等。
我们还可以利用random模块提供的sample和choice函数来简化上面的代码,前者可以实现无放回随机抽样,后者可以实现随机抽取一个元素,修改后的代码如下所示。
import random
red_balls = [i for i in range(1, 34)]
blue_balls = [i for i in range(1, 17)]
# 从红色球列表中随机抽出6个红色球(无放回抽样)
selected_balls = random.sample(red_balls, 6)
# 对选中的红色球排序
selected_balls.sort()
# 输出选中的红色球
for ball in selected_balls:
print(f'\033[031m{ball:0>2d}\033[0m', end=' ')
# 从蓝色球列表中随机抽出1个蓝色球
blue_ball = random.choice(blue_balls)
# 输出选中的蓝色球
print(f'\033[034m{blue_ball:0>2d}\033[0m')如果要实现随机生成N注号码,我们只需要将上面的代码放到一个N次的循环中,如下所示。
import random
n = int(input('生成几注号码: '))
red_balls = [i for i in range(1, 34)]
blue_balls = [i for i in range(1, 17)]
for _ in range(n):
# 从红色球列表中随机抽出6个红色球(无放回抽样)
selected_balls = random.sample(red_balls, 6)
# 对选中的红色球排序
selected_balls.sort()
# 输出选中的红色球
for ball in selected_balls:
print(f'\033[031m{ball:0>2d}\033[0m', end=' ')
# 从蓝色球列表中随机抽出1个蓝色球
blue_ball = random.choice(blue_balls)
# 输出选中的蓝色球
print(f'\033[034m{blue_ball:0>2d}\033[0m')